
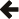

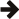
Basics
Images are essential in any image processing, vision and video project, and yet the variability in image representations makes it difficult to write imaging algorithms that are both generic and efficient. In this section we will describe some of the challenges that we would like to address.
In the following discussion an image is a 2D array of pixels. A pixel is a set of color channels that represents the color at a given point in an image. Each channel represents the value of a color component. There are two common memory structures for an image. Interleaved images are represented by grouping the pixels together in memory and interleaving all channels together, whereas planar images keep the channels in separate color planes. Here is a 4x3 RGB image in which the second pixel of the first row is marked in red, in interleaved form:
and in planar form:
Note also that rows may optionally be aligned resulting in a potential padding at the end of rows.
The Generic Image Library (GIL) provides models for images that vary in:
- Structure (planar vs. interleaved)
- Color space and presence of alpha (RGB, RGBA, CMYK, etc.)
- Channel depth (8-bit, 16-bit, etc.)
- Order of channels (RGB vs. BGR, etc.)
- Row alignment policy (no alignment, word-alignment, etc.)
It also supports user-defined models of images, and images whose parameters are specified at run-time. GIL abstracts image representation from algorithms applied on images and allows us to write the algorithm once and have it work on any of the above image variations while generating code that is comparable in speed to that of hand-writing the algorithm for a specific image type.
This document follows bottom-up design. Each section defines concepts that build on top of concepts defined in previous sections. It is recommended to read the sections in order.